IA générative
Quelques cas d'usage
& souveraineté
Godefroy de Compreignac
CEO @ Lonestone
2 juin 2025
Présentation de l'intervenant
Godefroy de Compreignac
Co-fondateur CEO @ Lonestone
Entrepreneur et développeur depuis 20 ans.
Early adopter enthousiaste de l’IA générative.
Agence de développement
de solutions web et IA


Île de Nantes
30+ experts salariés

Au programme
1. Cas d'usage
4. Choix des modèles
3. Confidentialité
2. Risques
Cas d'usage
LLM
Assistant d'entreprise
Les classiques
Fournis par les créateurs de modèles.


Les SaaS indépendants
Ils intègrent les plus gros modèles et fournissent des fonctionnalités supplémentaires.


✅ Dernières versions des modèles
❌ Limité aux modèles du fournisseur
❌ Pas ou peu extensible/personnalisable
✅ Nombreux modèles disponibles
✅ Style et prompts personnalisables
✅ Base de connaissance (RAG)
✅ Intégration d'outils tiers
⚠️ Double dépendance (SaaS + fournisseur de modèle)
Assistant d'entreprise custom
Développement sur mesure
Tout est possible, dans la limite de l'état de l'art.
Avec des outils open-source comme :
Framework : Vercel AI SDK, LangGraph, Mastra
Base de données : Postgres, Pinecone, Chroma
Évaluation : Langfuse, LangSmith
Interface graphique : React, Assistant-UI
✅ Branding / personnalisation totale
✅ Liberté de choix de modèles
✅ Maîtrise de la donnée
✅ Intégration d'outils internes
✅ Base de connaissance (RAG)
💰 Plus coûteux au lancement
🤔 Plus complexe
MCP Server
Sur mesure
Intégration de n'importe quelle API ou logiciel avec le protocole MCP.
SDK disponible dans de nombreux langages :
Clé en main
Intégrations de milliers d'outils répandus :
Pour connecter son assistant à tous ses outils (dits "tools").


Open source
À installer soi-même en local ou sur un serveur.
Liste de MCP servers :
Copilot dans une app
Dans l'éditeur de code
Pour coder plus vite et mieux.
Dans une app métier (CRM, ATS…),
sur mesure ou sur l'étagère
Pour retrouver ou consolider des informations, enregistrer des données, dicter, etc.
Solution intégrée au produit ou par un assistant externe.



Automatisations
Pour créer des workflows figés à exécuter régulièrement ou par déclencheurs.
n8n a l'avantage d'être open source et
de proposer un module Agent puissant :


Agents autonomes
Ils exécutent des actions complexes grâce à une planification
et à une délégation de tâches à des sous-agents.

⚠️ Demande des connaissances avancées en prompt engineering et souvent en code.

AutoGen
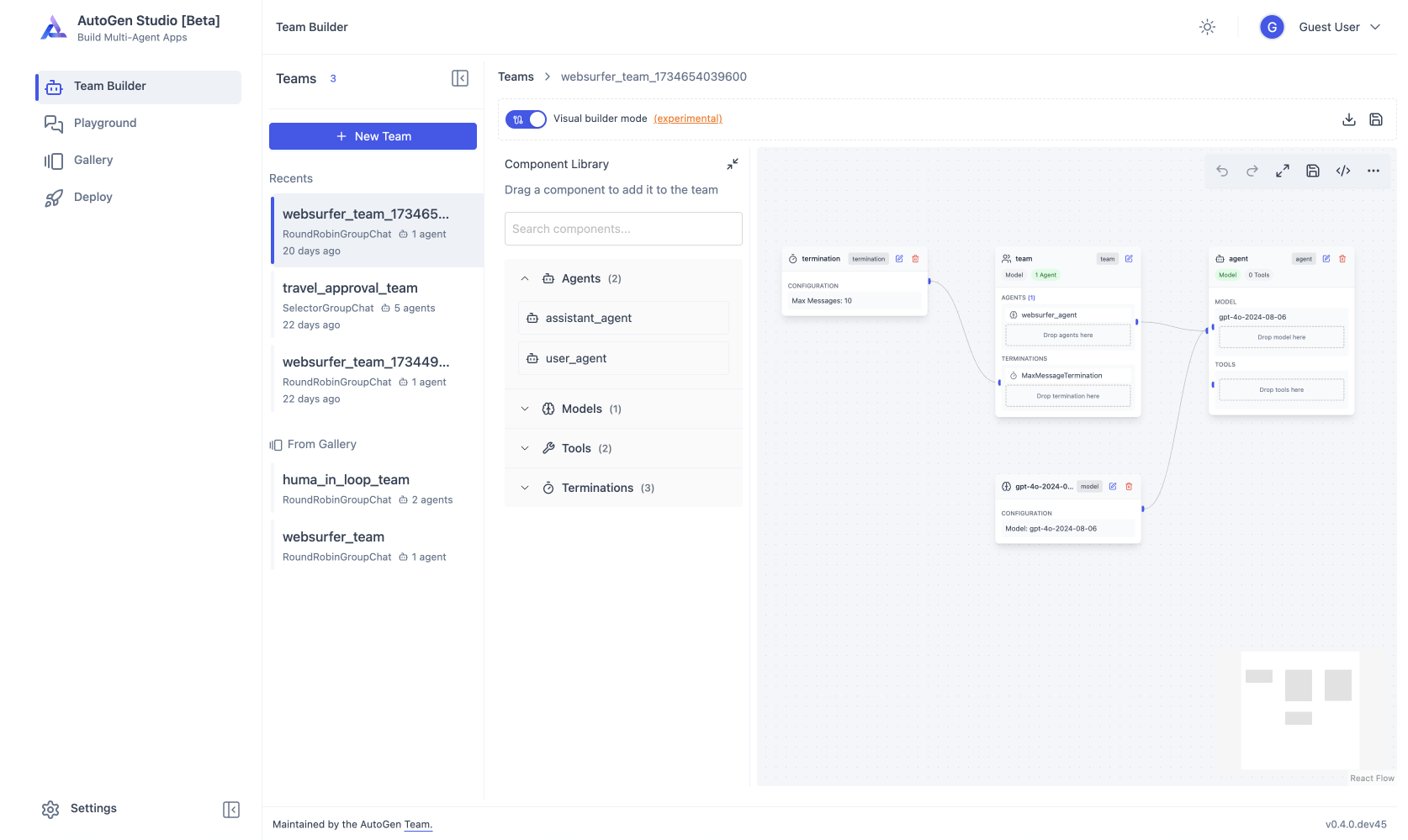
Cas d'usage
Voix
Transcription audio
Dictée
Pour prendre des notes à l'oral et éventuellement les retraiter avec un assistant IA.
SuperWhisper

Résumé de réunion
Pour enregistrer les réunions (visio et physique), les retranscrire, les résumer et les analyser.


ℹ️ La plupart utilisent l'API de transcription d'OpenAI et des appels LLM (OpenAI ou autre).
Pour plus de confidentialité/souveraineté, privilégiez des solutions qui tournent en local (Whisper en mode local) ou en France (Gladia).
Intégration sur mesure
Il est relativement facile d'intégrer des fonctionnalités de transcription dans une app avec les APIs de Gladia ou OpenAI par exemple.


Assistant vocal
Recevoir/passer des appels téléphoniques
Pour le support, la prise de commande, la prospection, etc.



Questionnaire vocal
Interview par une IA pour récolter des informations.
Exemples : CV, prise de brief, feedbacks, cas client…


Assistant vocal sur mesure
Modèles multi-modaux propriétaires
OpenAI Realtime API
https://platform.openai.com/docs/guides/realtime
Google Gemini Live
Orchestration de modèles
Micdrop (open source) pour intégrer dans une webapp
https://github.com/lonestone/micdrop
Nouveaux modèles de Kyutai, bientôt open source
Client
Serveur
API OpenAI Realtime
Client
Serveur
STT
LLM
TTS
Transcription
Génération de réponse texte
Génération
de la voix

Risques
Risques des LLM
Confidentialité & sécurité des données
- Fuite de données sensibles (clients, stratégie, RH…) si les données sont envoyées à un LLM non maîtrisé (via API par ex.).
- Shadow IT : les employés utilisent ChatGPT ou autres sans encadrement, en copiant-collant des infos confidentielles.
- Manque de contrôle sur le stockage et l’usage des données : certains LLM peuvent les utiliser pour affiner leurs modèles.
- Non-conformité RGPD : absence de base légale pour le traitement, transferts de données hors UE, absence d’opt-out clair.
Risques des LLM
Biais & responsabilité
- Décisions injustes ou discriminatoires (ex. recrutement, notation d’un partenaire, traitement différencié).
- Effet d’autorité : l’entreprise suit les suggestions du LLM sans vérification humaine.
- Biais implicites amplifiés par le modèle (langue, culture, genre, âge, etc.).
- Problèmes légaux si une décision automatisée basée sur un LLM est contestée.
Exemples de biais :
- Séréotypes de genre, ethniques, religieux, sociaux
- Biais culturels occidentaux ou spécifiques à un pays (ex: vision très américano-centrée)
- Angles de censure implicites (ex : éviter certains sujets sensibles dans des régimes autoritaires)
- Conception biaisée de l’histoire ou de la géopolitique
- Valeurs dominantes du pays d'origine (liberté individuelle vs. ordre collectif, conception de la vie privée, etc.),
- Sources peu fiables ou polarisées
Risques des LLM
Dépendance & pérennité
- Verrou technologique : dépendance forte à un fournisseur (OpenAI, Anthropic, etc.) sans alternative facile.
- Augmentation soudaine des prix (changement de politique commerciale ou tarification à l’usage).
- Modifications de comportement du modèle sans préavis (nouvelle version, perte de cohérence, performances différentes).
- Pas d’accès au modèle si le fournisseur décide de restreindre certains usages (usage militaire, politique, légal…).
Risques des LLM
Fiabilité & robustesse
- Hallucinations : le modèle peut inventer des données fausses mais formulées avec aplomb.
- Pannes ou indisponibilités (ex. surcharge du service, problème réseau, blocage géopolitique).
- Impossibilité d’expliquer certaines décisions : boîte noire, ce qui pose un problème de traçabilité et d’audit.
Risques des LLM
Image & réputation
- Production de contenus offensants ou inappropriés (même involontairement).
- Mauvaise gestion de la communication si un incident IA survient (ex : réponse déplacée à un client).
- Crise de confiance des utilisateurs ou partenaires si l’usage de l’IA est perçu comme opaque ou dangereux.
Risques des LLM
Conformité & régulation
- Non-respect de l’AI Act européen (niveau de risque mal évalué, absence de documentation, surveillance insuffisante).
- Manque de gouvernance IA : pas de politique, pas de référent, pas de procédure de validation.
- Absence de registre ou de traçabilité des prompts et des sorties utilisés dans des décisions importantes.
Risques des LLM
Qualité & contrôle des outputs
- Réponses incorrectes ou non conformes au ton ou à la marque.
- Incohérences dans les réponses à travers le temps ou entre utilisateurs.
- Problèmes de versionning des modèles et de reproductibilité.
Les géants (OpenAI, Meta…) dépensent beaucoup dans la "safety",
mais aucun ne fournit ses données d'entraînement.
La "safety" est dépendante de choix moraux et donc de ces organisations et de leurs pays d'origine.
Est-il sûr d'utiliser OpenAI (🇺🇸) ou DeepSeek (🇨🇳) ?
On ne sait pas vraiment.
➡️ Quelques solutions :
- Utiliser des modèles open source
- Évaluer les biais en contexte
- Systématiser la validation humaine dans les processus critiques
- Privilégier des modèles européens ou souverains
- Finetuner ou réentraîner partiellement
-
Surveiller et documenter les usages :
- Politique d’audit
- Gouvernance IA
- Système d'évaluation
Confidentialité
Où vont mes données ?
On peut distinguer en général :
- La base de données : peut rester confidentielle, jamais envoyée entièrement au LLM ni aux services tiers.
- Des extraits de la base de données : envoyés au LLM dans le contexte pour générer une réponse.
- Des données générées par le LLM (potentiellement provenant partiellement de la base de données) : envoyées à des tools.
- Les sessions (prompts + réponses du LLM) : stockées dans un outil d'évaluation.
Cas général
Client
Serveur
LLM (API)
Base de données
Services tiers (tools, eval)
➡️ Il existe plusieurs degrés de confidentialité.
Même en utilisant une API de LLM comme OpenAI, on peut garantir la confidentialité des données personnelles et éviter de faire sortir toute la base données de l'infrastructure de l'entreprise.
Maximiser la sécurité & la confidentialité des données
LLM
➡️ Utiliser au maximum des outils open source.
➡️ Tout héberger sur serveur ou cloud privé.
👎 Moins performant que OpenAI et Claude
Exemples de recommandations :
Exemples
À noter
Llama 3.3 70B
Base de données
RAG
Evaluations
Autres tools
Postgres
Ragflow
Langfuse
(voir slide MCP serveurs)
👍 Très classique
👍 Assez accessible, mais les technos évoluent vite
👍 Facile et suffisant pour la plupart des usages
🤔 Dépendant des solutions à connecter
Choix des modèles
Les types de modèles
LLM - Large Language Model
(Text-to-Text)
STT - Speech-to-text
TTS - Text-to-Speech
Text-to-Image
Traitements textuels :
-
Répondre à une question
-
Planifier
-
Appeler un outil
-
Générer du code
Retranscrire de l'audio en texte.
Générer de la voix, avec clonage, émotion, etc.
Générer des images
Image-to-Text
Analyser des images
Multimodal
Plusieurs capacités simultanées : texte, images, audio…
… et bien d'autres : Text-to-Video, Image-to-Video, Image-to-3D, Voice Activity Detection, etc.
📝 → 📝
🗣️ → 📝
📝 → 🗣️
📝 → 🖼️
Multimodal
Plusieurs capacités simultanées : texte, images, audio…
🖼️ → 📝
📝 🖼️ 🗣️
Les types de modèles
✅ Code source
✅ Poids du modèle
🤔 Données d'entraînement (parfois)
✅ Documentation complète
Open source
Open weight
Propriétaire
Accès
✅ Entrainement
✅ Fine-tuning
✅ Analyse
✅ Poids du modèle
❌ Code source, données
❌ Code, poids, données…
Ajustement
✅ Local (petits modèles)
✅ Auto-hébergement (compliqué)
✅ Offres cloud
Hébergement
✅ Fine-tuning
🤔 Fine-tuning (parfois)
✅ Local (petits modèles)
✅ Auto-hébergement (compliqué)
✅ Offres cloud
✅ Offres cloud
❌ Local, auto-hébergement
⚠️ Dépendance au fournisseur
Limiter la dépendance aux fournisseurs de modèles
Utilisation locale
➡️ Idéal pour un usage ultra confidentiel et pas trop exigeant.
⚠️ Possible uniquement avec des petits modèles et un hardware suffisant.
Auto-hébergement
➡️ Idéal pour une confidentialité maximale, un contrôle total, et une très forte consommation.
⚠️ Très compliqué et très coûteux.
Plateformes spécialisées
➡️ Idéal pour des modèles faits maison.
⚠️ La plupart sont aux USA.


Hébergeurs classiques
➡️ Idéal pour héberger en France avec capacité de scaling.
⚠️ Seulement quelques modèles disponibles





Exemples de choix LLM
Propriétaire
Type
Open weight
Open weight
Précision
🇺🇸
Origine



⭐ ⭐ ⭐ ⭐ ⭐
Rapidité
⭐ ⭐ ⭐ ⭐
⭐ ⭐ ⭐ ⭐
⭐ ⭐ ⭐ ⭐ ⭐
⭐ ⭐ ⭐
⭐ ⭐ ⭐ ⭐
🇺🇸 🇨🇳
🇫🇷
Cloud français
❌
✅ Scaleway, OVH
✅ Mistral, Scaleway, OVH
Coût
💰 💰 💰 💰
💰 💰
💰 💰
Idéal pour
Performances, scaling
Confidentialité, performance
Confidentialité, souveraineté 🇫🇷
Merci pour votre attention !
Restons discuter !
(Et suivez-moi sur Linkedin)
Godefroy de Compreignac
CEO @ Lonestone
Talk Technocampus 2 juin 2025
By lonestone
Private